En este artículo se explica cómo se pueden crear sitios y aplicaciones con un buen funcionamiento sin conexión.
En este artículo se explica cómo se pueden crear sitios y aplicaciones con un buen funcionamiento sin conexión, utilizando las siguientes funcionalidades de HTML5:
- AppCache para guardar los archivos en local y acceder a ellos en modo offline en forma de URLs
- IndexedDB para guardar datos estructurados en local y poder acceder y consultarlos
- El Almacenamiento de DOM (DOM Storage) para guardar pequeñas cantidades de información en formato de texto en el equipo
- Los Eventos Offline, para detectar si el equipo está conectado a la red

Ejemplo: soporte para acceso a las aplicaciones en modo offline
Vamos a suponer que salimos de compras con una copia de una receta que hemos sacado de un sitio web de recetas de cocina, pero estamos en el mercado, no encontramos algunos de los ingredientes, y resulta que no tenemos posibilidad de conectarnos con una red WiFi.Imagínate que cuando estabas en casa revisando las páginas del sitio de recetas desde tu tablet o un portátil, una parte del sitio se hubiera descargado automáticamente para seguir leyendo en modo offline. Así podrías llevarte el equipo a la tienda, acceder al mismo sitio para buscar otra receta distinta y comprar los ingredientes en el mercado. Lo bueno de esto es que puedes hacerlo sin estar conectado a la red. Como consumidor, seguramente para ti este sitio web tendrá más interés porque sigue funcionando cuando y donde tú lo necesitas.
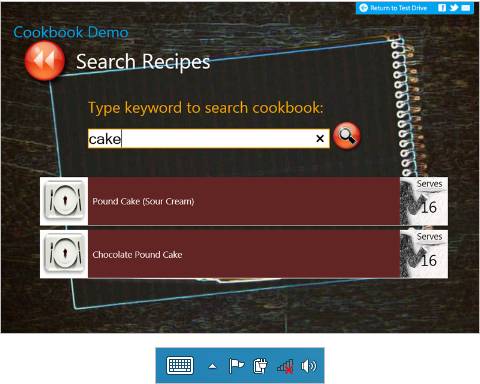
Resultados de búsqueda offline para la palabra “cake” en el sitio de recetas de cocina
Si eres un desarrollador, puedes poner en marcha escenarios de este tipo con una combinación de tecnologías offline: AppCache, IndexedDB, DOM Storage, y WebSockets (o XHR). Antes de analizar cada una de ellas, vamos a profundizar un poco en las ventajas.
En el caso de las aplicaciones y sitios web estilo Metro, las tecnologías offline nos permiten manejar los fallos en la conectividad. Imaginemos que un usuario está rellenando un formulario y pierde el acceso a la red. ¿Qué debería hacer el sitio web o la aplicación estilo Metro? Un enfoque de desarrollo independiente de la conexión nos permitiría trabajar correctamente tanto si estamos conectados a la red como si no.
En escenarios más complejos, los sitios y aplicaciones web permiten al usuario crear nuevos contenidos y almacenar datos, aun en condiciones de falta absoluta de conexión. Imagina Outlook Web Access (OWA), Hotmail o GMail funcionando sin problemas en modo offline, tal y como ya hace Outlook.
Las tecnologías offline pueden además mejorar el rendimiento global del sistema utilizando datos cacheados en local, precargando información que se utilizará más adelante y trasladando parte de la carga de procesamiento desde la nube (o la red) al dispositivo del cliente. Cuanta más información se mantiene en local, se busca en local y se procesa en local, menos recursos necesita el servidor y más rápida será la experiencia del usuario.
Existe un gran interés en que las aplicaciones estilo Metro puedan funcionar offline, mayor que en el caso de los sitios Web. Debido a que se distribuyen utilizando paquetes autocontenidos que se descargan desde las tiendas, los usuarios esperan que tengan algún tipo de funcionalidad en modo offline (hablamos de juegos, libros, recetas, etc.). Aunque estas aplicaciones no puedan crear o acceder a contenidos nuevos, los contenidos anteriores deberían estar accesibles (contactos, reuniones, noticias, artículos de prensa, etc.).
Cache local de archivos con AppCache
AppCache nos permite crear caches en local de larga duración o recursos de archivos descargados. A estos recursos podemos acceder sin conexión no utilizarlos también cuando estamos conectados, El uso de esta tecnología es tan sencillo como acceder al objeto windows.localStorage. En este objeto podemos consultar o añadir pares nombre-valor en forma de propiedades. El siguiente fragmento de código muestra cómo se almacenaría la puntuación del juego con localStorage:
<script type="text/javascript">
var lStorage;Actualizar datos en local con WebSockets y XHR
En ciertas circunstancias los datos de los usuarios seguirán residiendo en la nube a fin de que pueda acceder a ellos sin dificultad utilizando varios dispositivos. Por tanto, tenemos que asegurarnos de que los datos cacheados siguen siendo relevantes y están actualizados. Para ello necesitamos crear canales de sincronización de datos entre nuestras aplicaciones y la nube. Podemos hacerlo con WebSockets y XHR que nos ofrecen una forma de sincronización. Es preciso que empaquetemos los datos dentro de formatos transferibles (por ejemplo XML o JSON), utilizar XHR o WebSockets para transferir estos recursos al cliente y después utilizar parsers XML o JSON para crear los objetos JavaScript que se guardarán, finalmente en una base de datos IndexedDB. Esta técnica también se puede utilizar para subir al servidor la información guardada en el DOM Storage.
Conclusión
No siempre la conexión a la red es fiable, pero las aplicaciones sí tienen que ser fiables. Con las tecnologías offline que hemos explicado podemos anticiparnos a una interrupción de la conexión y hacer que nuestras aplicaciones funcionen mejor incluso, en muchos escenarios y situaciones de la vida real. Más aún: se nos abre una excelente oportunidad que podemos aprovechar para diferenciar nuestro sitio web y nuestras aplicaciones estilo Metro si conseguimos que funcionen bien sin conexión. Esta ventaja aumentará su utilización y aumentará la satisfacción de los usuarios. Utiliza las distintas tecnologías que he explicado en este artículo (AppCache, IndexedDB, DOM Storage y otras) para guardar en local tanta información como sea posible.Si quieres más información, puedes ver la presentación del BUILD llamada Building offline access in Metro style apps and Web sites using HTML5, que describe además el papel de la API File para resolver escenarios sin conexión.mejorando el rendimiento. Supón que un niño de tres años utiliza un portátil para descargar un juego interactivo (KidsBook por ejemplo) de la red de su casa. Si los recursos de la aplicación se almacenan en local, el niño puede seguir jugando cuando va en el coche, aunque no tenga acceso a la red.
Si KidsBook se hubiera desarrollado con AppCache, el juego habría cacheado todos los recursos necesarios (JavaScript, HTML, CSS, audio, video, etc.) para poder jugar durante la primera descarga y después, cuando no estuviera conectado a la red. Así el niño puede seguir entretenido aunque el dispositivo no tenga conexión.
function init() {
if (window.localStorage) {
lStorage = window.localStorage;
if (typeof lStorage.score == 'undefined')
lStorage.score = 0;
document.getElementById('score').innerHTML = lStorage.score;
}
}
function save() {
if (lStorage) {
lStorage.score = getGameScore();
}
}
</script>
...
<body onload="init();">
<p>
Your last score was: <span id="score">last score insert in init()</span>
</p>
</body>
Además, los eventos offline/online nos permiten detectar el estado de la conexión a la red, de manera que podemos enviar los datos al servidor o esperar. Por ejemplo, podemos detectar si tenemos conexión y actualizar la base de datos con contenidos del propio servidor utilizando WebSockets o XHR.
Es tan sencillo como comprobar el estado de la propiedad navigator.onLine. El código siguiente nos muestra cómo se registra la aplicación para los eventos online y offline:
function reportConnectionEvent(e) {
if (!e) e = window.event;
if ('online' == e.type) {
alert('The browser is ONLINE.');
}
else if ('offline' == e.type) {
alert('The browser is OFFLINE.');
}
}
window.onload = function () {
status = navigator.onLine; //retrieve connectivity status
document.body.ononline = reportConnectionEvent;
document.body.onoffline = reportConnectionEvent;
}
En el caso de las aplicaciones estilo Metro, ofrecemos una API adicional, llamada Windows.ApplicationData, que nos permite guardar en local más tipos de datos y que pueden migrar entre múltiples máquinas.
El punto clave consiste en diseñar la aplicación o el sitio Web con la idea de que la conectividad puede desaparecer en cualquier momento y tenemos que poder manejar esta situación de manera transparente para el usuario. Si implementamos un patrón de datos que almacena información en local antes de enviarla a la nube, tendremos una buena solución para situaciones donde el acceso a la red da problemas.
Actualizar datos en local con WebSockets y XHR
En ciertas circunstancias los datos de los usuarios seguirán residiendo en la nube a fin de que pueda acceder a ellos sin dificultad utilizando varios dispositivos. Por tanto, tenemos que asegurarnos de que los datos cacheados siguen siendo relevantes y están actualizados. Para ello necesitamos crear canales de sincronización de datos entre nuestras aplicaciones y la nube. Podemos hacerlo con WebSockets y XHR que nos ofrecen una forma de sincronización. Es preciso que empaquetemos los datos dentro de formatos transferibles (por ejemplo XML o JSON), utilizar XHR o WebSockets para transferir estos recursos al cliente y después utilizar parsers XML o JSON para crear los objetos JavaScript que se guardarán, finalmente en una base de datos IndexedDB. Esta técnica también se puede utilizar para subir al servidor la información guardada en el DOM Storage.Conclusión
No siempre la conexión a la red es fiable, pero las aplicaciones sí tienen que ser fiables. Con las tecnologías offline que hemos explicado podemos anticiparnos a una interrupción de la conexión y hacer que nuestras aplicaciones funcionen mejor incluso, en muchos escenarios y situaciones de la vida real. Más aún: se nos abre una excelente oportunidad que podemos aprovechar para diferenciar nuestro sitio web y nuestras aplicaciones estilo Metro si conseguimos que funcionen bien sin conexión. Esta ventaja aumentará su utilización y aumentará la satisfacción de los usuarios. Utiliza las distintas tecnologías que he explicado en este artículo (AppCache, IndexedDB, DOM Storage y otras) para guardar en local tanta información como sea posible.Si quieres más información, puedes ver la presentación del BUILD llamada Building offline access in Metro style apps and Web sites using HTML5, que describe además el papel de la API File para resolver escenarios sin conexión.mejorando el rendimiento. Supón que un niño de tres años utiliza un portátil para descargar un juego interactivo (KidsBook por ejemplo) de la red de su casa. Si los recursos de la aplicación se almacenan en local, el niño puede seguir jugando cuando va en el coche, aunque no tenga acceso a la red.
Si KidsBook se hubiera desarrollado con AppCache, el juego habría cacheado todos los recursos necesarios (JavaScript, HTML, CSS, audio, video, etc.) para poder jugar durante la primera descarga y después, cuando no estuviera conectado a la red. Así el niño puede seguir entretenido aunque el dispositivo no tenga conexión.
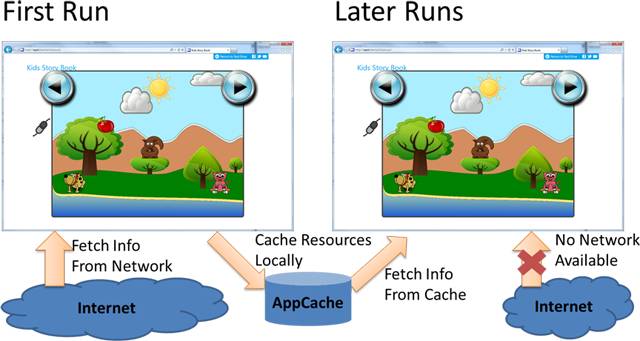
Flujo de creación de AppCache.
Si quieres saber cómo puede un juego Web interactivo funcionar sin conexión, puedes visitar el ejemplo de KidsBook en el sitio IE Test Drive.
AppCache emplea un archivo de manifiesto para indicar los URIs de los recursos con el fin de cachear sus contenidos desde un sitio web. El cacheo tiene lugar en un segundo plano después de que el navegador muestre la página Web, lo que hace permite la descarga de los archivos declarados en el manifiesto. Así se garantiza que los recursos están disponibles en la máquina local, en forma de bloque unitario en una misma transacción, para crear una cache local. Si falla la descarga de alguno de los recursos, no se genera la cache. Para actualizar el contenido almacenado en la cache hay que modificar el archivo de manifiesto en el servidor. Cuando el usuario vuelve a acceder al sitio web, el navegador compara el archivo de manifiesto del servidor con la última versión cacheada, Si la copia cacheada del manifiesto es distinta de la del servidor, se crea una nueva versión de la cache utilizando el contenido declarado en el archivo de manifiesto del servidor.
AppCache permite además que internet Explorer y las aplicaciones estilo Metro puedan acceder en modo offline a los recursos cacheados utilizando las direcciones URL de siempre. Gracias a ello podemos escribir una dirección web en el navegador y acceder a esta información sin conexión a la red. Además, las páginas offline pueden resolver URIs utilizando la información cacheada local. Puedes ver ejemplos de código en la sección Cache de Aplicación de HTML5 (“AppCache”) en la Guía de Desarrollo de IE10.
Pero sobre todo, AppCache ofrece una serie de ventajas con respecto a la cache de HTTP. La cache de HTTP no garantiza que los recursos cacheados puedan quedar disponible una vez se eliminan los archivos temporales (TIF, Temporary Internet Files). Aparte, los archivos sin conexión de HTTP no resuelven correctamente las direcciones URL cuando no hay conexión. No obstante, el cacheo de HTTP se puede utilizar para mejorar la respuesta de AppCache especificando el tiempo de vida de un recurso cacheado. Este parámetro determina si el recurso se descarga de la Web o se copia desde la cache cuando se crea una nueva versión de la cache local.
Las aplicaciones estilo Metro pueden aprovechar AppCache para cargar en local recursos web a los que acceden en iframes, y de esta manera pueden trabajar sin conexión.
Carga en local de grandes cantidades de datos estructurados con IndexedDB
IndexedDB es una base de datos local diseñada para almacenar objetos JavaScript en la máquina local, agilizando el indexado y la búsqueda de dichos objetos. El sitio de recetas de cocina que comentábamos al principio, incluye una base de datos con dieciséis recetas obtenidas de un sitio padre. Imaginemos que utilizamos una fuente de noticias RSS, un WebSocket, o una conexión XHR para actualziar esta base de datos cada cierto tiempo. Así los usuarios tendrían acceso a las recetas más recientes aunque no estén conectados a la red.IndexedDB nos permite manipular e indexar objetos Javascript directametne. Una ventaja de utilizar IndexedDB de forma directa para buscar información en local es que reduce los costes de computación ya que no nos obliga a buscar siempre en la nube. Se supone que podemos mantener la relevancia de la información cacheada en el sistema local.
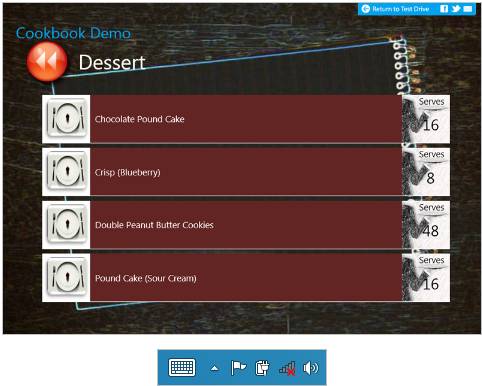
Muestra una lista de recetas almacenadas en la máquina local accesibles con IndexedDB.
IndexedDB es una tecnología creada empleando los conceptos de base de datos ISAM. Al igual que sucede con muchas tecnologías de plataforma Web, está diseñado de manera que ofrece una API de bajo nivel que se puede utilizar para desarrollar librerías con un mayor nivel de abstracción a partir de ella. En la tabla siguientes se comparan los conceptos de desarrollo de IndexedDB con conceptos análogos del Modelo Relacional que todos conocemos
| Concepto | BD Relacional | IndexedDB |
| Base de datos | Base de datos | Base de datos |
| Tablas | Las tablas contienen filas y columnas | objectStore contiene objetos Javascript y claves |
| Mecanismos de consulta, Join y filtros | SQL | APIs de cursor, APIs de rango de clave y código de aplicación |
| Tipos de transacciones y bloqueos | El bloqueo se puede producir a nivel de base de datos, tablas o filas en transacciones READ_WRITE | El bloqueo se puede producir en la base de datos con una transacción VERSION_CHANGE, o a nivel de objectStores con transacciones READ_ONLY y READ_WRITE. No hay bloqueo a nivel de objeto |
| Ejecución de transacciones (“commit”) | La creación de una transacción es explícita. Por defecto no se ejecuta salvo que se realice un commit | La creación de una transacción es explícita. Por defecto se ejecuta salvo que se haga una llamada a “abort” o se produzca una excepción no tratada. |
| Examen de propiedades | SQL | Se necesitan índices para consultar directamente las propiedades de los objetos |
| Registros/Datos | Forma normal y un valor único en cada propiedad | Forma no normalizada y pueden tener propiedades multivaluadas |
A la hora de utilizar IndexedDB se crean bases de datos que contienen almacenes de objetos (Contactos, correos, citas, etc.). Dichos almacenes de objetos contienen los objetos JavaScript que necesita la aplicación (Contactos –Nombre, Apellido, Dirección, etc.). Cada objeto JavaScript se supone que tiene un identificador único accesible mediante una clave keyPath. Además, los almacenes de objetos contienen índices para aquellas propiedades que se pueden utilizar para hacer consultas contra la base de datos (Emails: asuntos, fechas, etc.). Los filtros se pueden utilizar para organizar o reducir el bloque de resultados por medio de Rangos de clave (“KeyRanges”) en los índices o en el almacén de objetos.
El siguiente ejemplo de código muestra cómo se puede leer un registro de un libro de una base de datos “Library”:
var oRequestDB = window.indexedDB.open("Library");
oRequestDB.onsuccess = function (event) {
db1 = oRequestDB.result;
if (db1.version == 1) {
txn = db1.transaction(["Books"], IDBTransaction.READ_ONLY);
var objStoreReq = txn.objectStore("Books");
var request = objStoreReq.get("Book0");
request.onsuccess = processGet;
}
};
El acceso a la información contenida en almacenes de objetos siempre es en modo de lectura o escritura en el contexto de una transacción. Tenemos tres tipos de transacciones:
- VERSION_CHANGE – se utiliza para crear o actualizar el almacén de objetos y los índices. Puesto que las transacciones VERSION_CHANGE bloquean toda la base de datos y evitan la ejecución simultánea de varias operaciones, no se recomiendan para leer y escribir registros en la base de datos.
- READ_WRITE – permite añadir, leer, modificar y borrar registros contenidos en el almacén de objetos.
- READ_ONLY – Permite la lectura de objetos del almacén.
En suma, IndexedDB es un mecanismo optimizado para consultar objetos de datos utilizando índices. Aporta las APIs necesarias para acceder a grandes cantidades de datos estructurados por medio de cursores y para filtrar los datos utilizando objetos KeyRange. Creemos que los desarrolladores se decantarán por tener una base de datos “master” con todos los registros del usuario residiendo en la nube y una base local IndexedDB con una parte de los registros, para agilizar las búsquedas y el uso offline de los datos.
Almacenamiento de pequeñas cantidades de datos de texto en local, con DOM Storage y eventos Offline/Online
Los sitios web pueden utilizar el almacenamiento del DOM (DOM Storage) y los eventos de conectividad para mantener pequeñas cantidades de datos en formato de texto y detectar posibles problemas de conectividad. Imaginemos un juego que utiliza estas tecnologías para llevar la cuenta de la puntuación del usuario cuando no está conectado. Supongamos qué ocurriría si ha logrado una puntuación muy elevada y no tiene conexión a la red ¿la página Web se cuelga o simplemente devuelve un error?Ya que los datos son de naturaleza no estructurada (textos) y no necesitan mucho espacio, podemos utilizar el DOM Storage para guardar en local esta información sin necesidad de estar conectados, y subirla al sitio web en un momento posterior, cuando se recupere la conexión a la red. DOM Storage soporta una cantidad de datos superior a las cookies y no necesita codificarlos de ningún modo. Aparte, el DOM Storage no envía datos al servidor a cada petición y se puede restringir para acceso a nivel de dominio o de sesión.
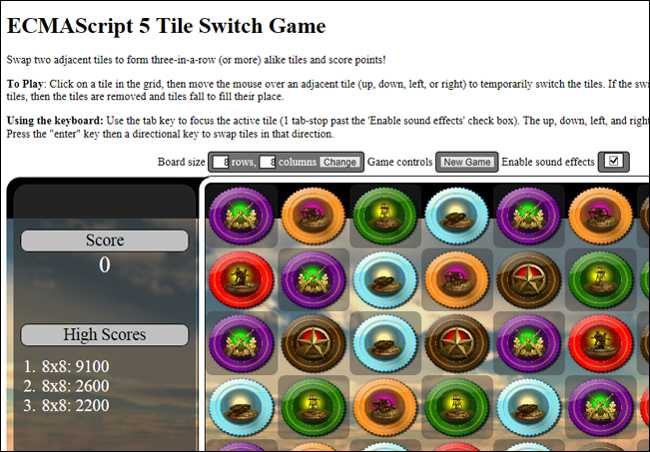
<script type="text/javascript">
var lStorage;
function init() {
if (window.localStorage) {
lStorage = window.localStorage;
if (typeof lStorage.score == 'undefined')
lStorage.score = 0;
document.getElementById('score').innerHTML = lStorage.score;
}
}
function save() {
if (lStorage) {
lStorage.score = getGameScore();
}
}
</script>
...
<body onload="init();">
<p>
Your last score was: <span id="score">last score insert in init()</span>
</p>
</body>
Además, los eventos offline/online nos permiten detectar el estado de la conexión a la red, de manera que podemos enviar los datos al servidor o esperar. Por ejemplo, podemos detectar si tenemos conexión y actualizar la base de datos con contenidos del propio servidor utilizando WebSockets o XHR.
Es tan sencillo como comprobar el estado de la propiedad navigator.onLine. El código siguiente nos muestra cómo se registra la aplicación para los eventos online y offline:
function reportConnectionEvent(e) {
if (!e) e = window.event;
if ('online' == e.type) {
alert('The browser is ONLINE.');
}
Muestra una lista de recetas almacenadas en la máquina local accesibles con IndexedDB.
else if ('offline' == e.type) {
alert('The browser is OFFLINE.');
}
}
window.onload = function () {
status = navigator.onLine; //retrieve connectivity status
document.body.ononline = reportConnectionEvent;
document.body.onoffline = reportConnectionEvent;
}
En el caso de las aplicaciones estilo Metro, ofrecemos una API adicional, llamada Windows.ApplicationData, que nos permite guardar en local más tipos de datos y que pueden migrar entre múltiples máquinas.
El punto clave consiste en diseñar la aplicación o el sitio Web con la idea de que la conectividad puede desaparecer en cualquier momento y tenemos que poder manejar esta situación de manera transparente para el usuario. Si implementamos un patrón de datos que almacena información en local antes de enviarla a la nube, tendremos una buena solución para situaciones donde el acceso a la red da problemas. Actualizar datos en local con WebSockets y XHR En ciertas circunstancias los datos de los usuarios seguirán residiendo en la nube a fin de que pueda acceder a ellos sin dificultad utilizando varios dispositivos. Por tanto, tenemos que asegurarnos de que los datos cacheados siguen siendo relevantes y están actualizados. Para ello necesitamos crear canales de sincronización de datos entre nuestras aplicaciones y la nube. Podemos hacerlo con WebSockets y XHR que nos ofrecen una forma de sincronización. Es preciso que empaquetemos los datos dentro de formatos transferibles (por ejemplo XML o JSON), utilizar XHR o WebSockets para transferir estos recursos al cliente y después utilizar parsers XML o JSON para crear los objetos JavaScript que se guardarán, finalmente en una base de datos IndexedDB. Esta técnica también se puede utilizar para subir al servidor la información guardada en el DOM Storage.
Conclusión
No siempre la conexión a la red es fiable, pero las aplicaciones sí tienen que ser fiables. Con las tecnologías offline que hemos explicado podemos anticiparnos a una interrupción de la conexión y hacer que nuestras aplicaciones funcionen mejor incluso, en muchos escenarios y situaciones de la vida real. Más aún: se nos abre una excelente oportunidad que podemos aprovechar para diferenciar nuestro sitio web y nuestras aplicaciones estilo Metro si conseguimos que funcionen bien sin conexión. Esta ventaja aumentará su utilización y aumentará la satisfacción de los usuarios. Utiliza las distintas tecnologías que he explicado en este artículo (AppCache, IndexedDB, DOM Storage y otras) para guardar en local tanta información como sea posible.Si quieres más información, puedes ver la presentación del BUILD llamada Building offline access in Metro style apps and Web sites using HTML5, que describe además el papel de la API File para resolver escenarios sin conexión.
Israel Hilerio
Principal Program Manager, Internet Explorer